

World's first family of multicore CPUs
based on POSIT number system.

SupersoniK- the ultimate multicore CPUs for
High Performance Computing (HPC) applications
with accuracy exceeding that of double precision
floating point numbers.

RacEr- the world's first POSIT for Graphics
Processing Unit (GPU). RacEr is shipped with
highly silicon efficient architecture.

FalKon- the best in class multicores for Artificial
Intelligence (AI) applications capable of
parameterization of processing elements.

Tez- has top-notch accuracy making
it highly desirable for timing critical
applications.
VividSparks is a self funded, high-speed computing technology company that specializes in fabless semiconductors. We are oriented towards solving fundamental problems in arithmetic circuit designs. We have libraries and algorithms that are highly silicon efficient and brilliant performing. At VividSparks, our technology is built with the goal of delivering high performance to users with minimum power consumption possible. We believe technology has to be novel – not expensive. And novel technology should be accessible and affordable to everyone. VividSparks wants to create a least power consuming, less silicon area consuming computing world, at the same time deliver top class performance.

Dr. Vijay Holimath, President and the CEO, has over 20 years of experience in designing and implementing high performance computing machines and network on chip for scientific computing and automotive applications. During his career, his research was mainly focused on design and implementation of efficient mobile computing algorithms. He has published several papers in research journals. Dr. Holimath has worked with many French, Japanese and US educational institutions. He has prepared and presented several business plans to the investors in the past.
He holds a Doctorate in Computer Science from the University of Santiago de Compostela (Spain), a Masters in Computer Science from the University of Newcastle (UK) and a Bachelors in Electronic Engineering from the Karnataka University (India). Prior to founding of VividSparks, Dr. Holimath has worked as a Research and Development Engineer in National Institute of Informatics, Tokyo (Japan).

Mr. Kumar Senthil is investor and director of VividSparks USA. He is an Angel Investor, Startup mentor, Board member, Strategic startup Advisor and Entrepreneur. He spent 25+ years as a HiTech executive in Product Strategy and development, creating new products and driving Global business generating $B in new revenue. He has founded 4 startups and was part of many familiar Global F-100s including Intel/WindRiver (founding team Autonomous Driving), Qualcomm (founding team Qualcomm Health, Qualcomm Automotive), Motorola (founding team 4G WiMax and LTE) and more. Kumar's recent areas of interest have been in AI compute (founder, NeuEdgeAI), Health Tech (co-founder, KidneyPal) and eCommerce (founder, Kunneckt). He also serves as an advisor to 2 other Startups in the Sacramento, CA region. He shares his time between Northern California and Washington (Seattle) and is highly interested in supporting local communities and startups that are aligned with his vision of creating innovative products and services that improve the quality of our every day lives. Kumar graduated from Texas A&M (USA) and Anna Univ (India).

Mr. Irfan Malik is investor and director of VividSparks Australia, he as over 25 years of experience in Digital Tech & Innovative Business Solutions. Throughout his career he helped many start-ups to succeed in business. He is also head of Australia India Business Council (AIBC) National Associate Chair President NSW. He has very good understanding of Australian needs and requirements. He is supporting & mentoring over 80 plus start-ups globally including Start-ups in Indian & Australia with several seed investments into various ventures. He holds Bachelor of Engineering from Coimbatore Institute of Technology (India) and Master's from University of Newcastle (Australia).

Prof. John Gustafson, Chief Scientist, is the inventor of POSIT number system, Gustafson's Law, introducing the first commercial computer cluster, measuring with QUIPS, leading the reconstruction of the Atanasoff-Berry Computer, and several awards for computer speedup. Prof. Gustafson has recently finished writing a book, The End of Error: Unum Computing, that presents a new approach to computer arithmetic: the unum. The universal number, or unum format, encompasses all IEEE floating-point formats as well as fixed-point and exact integer arithmetic. This approach obtains more accurate answers than floating-point arithmetic yet uses fewer bits in many cases, saving memory, bandwidth, energy, and power.
Prof. Gustafson previously held the positions of Senior Fellow and Chief Product Architect at AMD in Sunnyvale, CA, Director at Intel Labs-SC, CEO of Massively Parallel Technologies, Inc. and CTO at ClearSpeed Technology. Currently, he is professor in Arizona State University. He holds a Doctorate and Masters in Applied Mathematics from Iowa State University (USA) and BS from California Institute of Technology (USA).
What is VividarithmetiK?

VividarithmetiK is a next generation processors that computes basic arithmetic functions such as addition, subtraction, multiplication, division, square root, trigonometric functions, compare and convert instructions using a new number system called POSIT, that is highly silicon efficient and brilliant performing. VividarithmetiK has a family of processors called Supersonik, RacEr, FalKon and Tez with different POSIT configurations specifically targeted towards HPC, Graphics, AI and Automotive applications respectively. VividarithmetiK eliminates carry propagation in adders and multipliers using novel adder called Carry Free Adder (CFA). CFA not only eliminates carry propagation but also consumes very less power. We build top performing chips by implementing super-fast arithmetic libraries in them rather than fabricating chip in higher technology nodes. Read more...
All the following products are shipped with VividKompiler, world's first native POSIT C,C++ and Fortran compiler.

64 POSIT cores which provide server-class performance that is unmatched in it's efficiency and size
FPGA IP BUY
Stand-alone IP BUY

Premium GPU architecture configurable up to 512 cores
FPGA IP BUY
Stand-alone IP BUY
All our cores have the following capabilities to compute the following arithmetic operations with different POSIT configurations which are suited for different solutions.

All our cores are super efficient when it comes to energy and offer massive boost in performance, at the same time providing highly accurate results and fewer exceptions than Floating Point numbers.
HPC

Basic Linear Algebra Subprograms (BLAS) and Linear Algebra Package (LAPACK) form basic building blocks for several HPC applications and hence dictate performance of the HPC applications.Weather and climate models are another HPC applications and forecast quality depends on resolution and model complexity. Resolution depends on the performance of Floating Point Unit (FPU). The HPC community is using double precision as default since decades. Using double precision requires lot of power and performance. SupersoniK is the ultimate co-processor due to its capability to compute most complicated tasks in HPC with 32 bit POSIT. Each core in SupersoniK with it’s VividarithmetiK technology has the capability to execute two independent operations with only one instruction and each core has up to 5X speed compared to state-of-the-art processors, accelerators and GPUs, all by consuming very minimal power.
Graphics

Computer graphics is known to be computation-intensive, and thus GPU has been widely used in PCs, mobiles and other server machines to speed-up 3D graphics operations. Recently, there is an increasing demand for real-time 3D graphics. The GPU designs usually contain Vectored Processing Unit (VPU) for Dot-Product (DP) calculation, a key operation in graphics transformation. Another computation-intensive operation in 3D graphics is the lighting that usually requires advanced operations such as logarithm, exponentials, square-root and reciprocals, which are usually realized in special function units. RacEr is ideally suited for DP and advanced operations. RacEr achieves the computation at lightning speed with minimal power using VividarithmetiK's Technology. When RacEr is connected in a network, the flexible architecture of RacEr allows each core to make two different computations with only one instruction.
Artificial Intelligence

AI is used in a variety of applications such as algorithmic trading, self driven cars, security surveillance, etc. Deep learning, a subset of machine learning, has progressed rapidly during the past decade due toBig data, Deeper nets, Clever training. In deep learning, the key computational kernels involve linear algebra, including matrix and tensor arithmetic. A deep neural net can have millions or even billions of calculations due to their rich connectivity. While depth refers to the number of layers, the layers can also be quite wide – with hundreds to thousands of neurons in a given layer. The weights of these connections must be adjusted iteratively until a solution is reached in a space of very high dimensionality. Because of the large number of calculations, generally modest accuracy is required for the final output. Typically, 16 bit precision suffices. FalKon plays a significant role in computation of AI with only 16 bit POSIT. FalKon not only computes at low precision but is also highly accurate with larger dynamic range compared to half precision floating point arithmetic.
Automotive
Having a great car is many people’s dream and the most complicated electronic part in a car is Electronic Control Unit (ECU) also a CPU. The ECU is responsible for many mathematical calculations involving partial differential equations and multiple integrals for engine, drive train, power train, gear box and traction control. These calculations are bounded to very strict timing constraints. Tez cake walks these calculations with an enormous speed by using VividarithmetiK Technology. With the brand new VividSparks POSIT compiler along with POSIT compare instructions, ECU can make far better decisions in timing critical situations.
Our partnerships with Universities are main pillars of our innovations and also where we meet the next generation of researchers. If you are interested in collaborations drop us a message ...we are excited to work with you.We have collaborations with following Professors:

Prof. Fujita is head of Fujita Laboratory in University of Tokyo, Japan . His research interests include: VLSI implementation, Microprocessor and System Design.

Prof. Chen is Associate Professor in National Chung Cheng University, Taiwan . His research interests include: Multicore programming, Program analyses, Compiler optimizations, and Software reliability.

PD Dr. Korch is a member of the Chair for Parallel and DistributedSystems at the University of Bayreuth, Germany . His research interests include: Parallel computing, systems of ordinary differential equations, irregular algorithms and distributed systems.

Dr. Duchkov is a Senior Researcher in IPGG, Siberian Branch of the Russian Academy of Sciences, Russia . His research interests include: seismic methods and geothermic,Seismic imaging, seismic data regularization using Gaussian Wave Packets, microseismic monitoring of hydrofrac, etc.

Prof. Yadav is Director in ViBram Silicon Hub, Govt. of India, Raipur, India . Her research interests include: Networks-on-Chip, Computer Architecture, Computer Vision, Machine Learning, Artificial Intelligence.

Prof. Al-Ars is Associate Professor in TU Delft, Netherlands . His research interests include: multicore systems to accelerate big data applications, multicore architectures (CPU, GPU, FPGA), design and optimization of interconnect solutions to improve system performance and relieve data transfer bottlenecks.

Prof. Assaf is Associate Professor of Centre for Information and Communications Technology in The University of the South Pacific, Fiji . His research interests include: computer architecture, mixed-signal analysis, hardware/software co-design and test, fault-tolerant computing, distributed detection in sensor networks, and RFID technologies.

Prof. Norris is Associate Professor in University of Oregon, USA . Her research interests include: source code analysis and transformation, specifically on automatic differentiation, performance analysis, and empirical code tuning; embeddable domain-specific languages for high-performance computing; and quality of service infrastructure for scientific software (including numerical software taxonomy and automated configuration), for optimizing performance, energy use, and resilience of complex applications.

Mlian Klowewer is climate scientist in MIT . His research interests include: meteorology, physical oceanography and climate physics.

Prof. Fernanda Lima Kastensmidt is Professor in Universidade Federal do Rio Grande do Sul, Brazil . Her research interests include: soft error mitigation techniques for SRAM-based FPGAs and integrated circuits, such as microprocessors, memories and network-on-chips (NoCs), and the analysis and modeling of radiation effects in those circuits.

Prof. Alberto A. Del Barrio is Associate Professor in Universidad Compultense De Madrid, Spain . His research interests include: high performance computing, computer architecture and system design.

Prof. Amos Omondi is Professor in The State University of New York, Korea . His research interests include: application-specific hardware architectures and arithmetic for signal processing applications.
The success of a company is guaranteed when the right people join hands –partners who help us come up with synergistic solutions to a multitude ofchallenges in the industry and convert them into opportunities. We offer a wide range of partnership opportunities for those interested in building chips to being service providers to help manage these chips. We rely on our network of partners to reach our goals, and to enable our customers to achieve theirs. Strong relationships are crucial to the success of our customers. Drop us a message to connect with us, we would be excited to join hands with you. We laid out VividSparks Corporate and Products branding guidelines for our partners, more information is at VividSparks Corporate and Products Branding Guidelines .We are looking for partnerships in the following areas:

Silicon partners to deliver VividSparks-based Systems on Chips (SoCs) optimized for targeted market opportunities.
CONTACT
EDA tool vendors to integrate our libraries in their tools and license our IP cores to their customers directly.
CONTACT
Distributors and agents globally to provide access to our technology through partner products.
CONTACT
VividSparks development boards are going to be the ideal platform for accelerating the development and reducing the risk of new SoC designs. VividSparks development boards will help customers save time and effort by getting to production sooner and with less manufacturing overhead.
CONTACT
Partners in development tool solutions are designated to accelerate engineering from SoC design through to software application development.
CONTACT
Network of software partners to provide customers a wide range of products to get to market faster than the competition.
CONTACT
Our service provider partners aid VividSparks customers in understanding our product integration into their system, take up development requests if need arises and also offer post development support.
CONTACT
Experienced technology trainers to offer training on a wide range of VividArithemtiK technology topics on product usage.
CONTACT
Everything in the world can be represented using Mathematics, from the smallest, for instance, thesymmetry of a leaf, to the largest, for instance, the complexity of human brain. Math is required for thesimplest day to day calculations to the more complicated 3D graphics and scientific computing. Computers compute math using IEEE-754 Floating Point (FP) number system. The FP system has limited dynamic range, less accurate results and does not properly obey mathematical laws. Due to these limitations scientists, programmers and algorithmist need to adjust their models compromising on accuracy. Posit number system on other hand provides much better accuracy with same data width as that of FP system which leads to higher performance with silicon area. Read more...
FFT
The computation of the Discrete Fourier Transform (DFT) using the Fast Fourier Transform (FFT) algorithm has become one of the most important and powerful tools of HPC. FFTs are investigated to demonstrate the speed and accuracy of POSIT arithmetic when compared to floating-point arithmetic. Improving FFTs can potentially improve the performance of HPC applications such as CP2K, SpecFEM3D, and WRF, leading to higher speed and improved accuracy. “Precision” here refers to the number of bits in a number format, and “accuracy” refers to the correctness of an answer, measured in the number of correct decimals or correct bits. POSIT arithmetic achieves orders of magnitude smaller rounding errors when compared to floats that have the same precision. Read more...
Edge Computing

Computer arithmetic is ubiquitous in applications ranging from an embedded domain such as smartphones to HPC applications like weather modeling. Specifically, in embedded systems, since the platforms have performance limitations due to limited power and area budgets, using appropriate arithmetic is desirable. Major semiconductor manufacturers involved in efficient domain-specific accelerator designs are investigating new arithmetic formats for their applications of interest. For example, the recently proposed bfloat16 format supports similar dynamic range as single-precision IEEE 754 compliantfloating point number, but with lower precision. The bfloat16 format is supported in several products by Intel, Google, and ARM. Read more...
Autonomous Driving

The use of deep neural networks (DNNs) as a general tool for signal and data processing is increasing in automotive industry. Due to strict constrains in terms of latency, dependability and security of autonomous driving, machine perception (i.e. detection or decisions tasks) based on DNN can not be implemented relying on a remote cloud access. These tasks must be performed in real-time on embedded systems on-board the vehicle, particularly for the inference phase (considering the use of DNNs pre-trained during an off-line step). When developing a DNN computing platform, the choice of the computing arithmetics matters. Moreover, functional safeapplications like autonomous driving pose severe constraints on the effect that signal processing accuracy has on final rate of wrong detection/decisions. Read more...
HPC

Floating point computations required in many applications. Floating-point representations builds onthe work done in the 1970s and 1980s, before the IEEE standard was developed and codified in hardware. The choices made in IEEE leave much to be desired when accurate arithmetic and reproducibility of numerical computations are paramount, including support for an excessive number of not-a-number (NaN) representations, gradual underflow but not overflow, expensive exceptions such as subnormals, ambiguity due to two representations of zero, etc. POSIT representation have shown to provide a better trade-off between precision and dynamic range, and in effect increase the accuracy per bit stored. Read more...
Weather and Climate Modeling
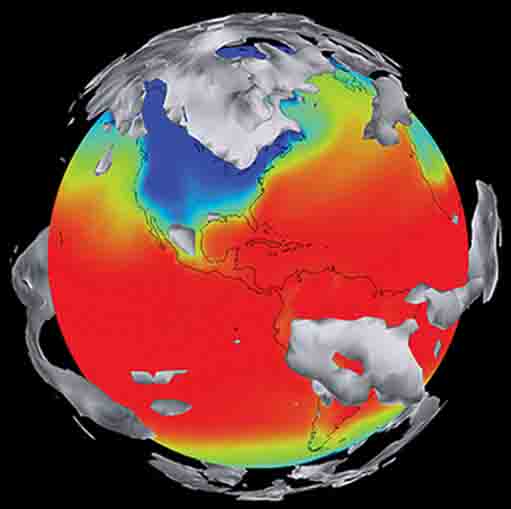
The forecast error of a weather forecast model has several origins: (i) Initial and boundary condition errors, which result from observations, data assimilation and external factors; (ii) model error, i.e. the difference between the mathematical model and the real world; (iii) discretization error resulting from a finite spatial and temporal resolution of the discretized equations and (iv) rounding errors with finite precision arithmetic. In general, the forecast error is dominated by (i-iii), depending on the forecast variable and the forecast lead time. In contrast, rounding errors are usually negligible with the IEEE 754 standard on 64bit double precision floating point numbers, which is still the standard for the majority of operational weather forecasts and in climate models. Read more...
HPC
We have discussed performance and energy consumption of GPU and SupersoniK via implementing financial market models. The case studies used in this comparison arethe Black-Scholes model and the Heston model for option pricing problems, which are analyzed numerically by Monte Carlo method. The final implementations of both models to several options onSupersoniK achieved the best parallel acceleration systems, in terms of performance-per-operation and energy-per-operation. Read more...
Automotive Computing

We have implemented electronic control unit (ECU) architecture for real-time automotive cyber-physical systems that incorporate security anddependability primitives with low resources and energy overhead. We quantify and compare temporal performance, and energy of Tez architecture for a steer-by-wire case study over CAN, CAN FD, and FlexRay in-vehicle networks. Implementation results reveal Tez can attain a speedup of 3.2× and 5.1×, respectively, while consuming 2.3× and 3.4× less energy, respectively, than the contemporary ECU architectures. Read more...
GPU Computing
Heterogeneous or co-processor architectures are becoming an important component of high productivity computing systems. In this work the performance of a GPU is compared with the performance of a RacEr. A set of benchmarks are employed that use different process architectures in order to exploit the benefitsof RacEr. We show that the RacEr is more productive than the GPU for most of the benchmarks and conclude that FPGA-based GPU is best suited for GPU computing. Read more...
AI Computing

Neural networks (NN) are highly parallel workloads which require massive computational resources for training and oftenutilize customized accelerators. FalKon is best suited for NN, a set of benchmarks are employed that use different process architectures in order to exploit the benefits of FalKon. To help provide a fair baseline comparison, we conducted comprehensivebenchmarks of performance and energy of NN [Inception-v2 and ResNet-50, ResNet-18, Mobilenet-v2 and SqueezeNet], the FalKon is 2.1×–2.9× faster and 1.1×–2.2× more energy efficient than GPU implementations when running Inception-v2, ResNet-50, ResNet-18, Mobilenetv2 and SqueezeNet. Read more...

The GPU has become an integral part of today’s mainstream computing systems. The modern GPU is not only a powerful graphics engine but also a highly parallel programmable processor featuring peak arithmetic and memory bandwidth that substantially outpaces its CPU counterpart. The GPU’s rapid increase in both programmability and capability has spawned a research community and industries that has successfully mapped a broad range of computationally demanding, complex problems to the GPU. This effort in general-purpose computing on the GPU, also known as GPU computing, has positioned the GPU as a compelling alternative to traditional microprocessors in high-performance computer systems of the future. Leaders in computing are now profiting from their investments in new number systems initiated half a decade ago. We introduce revolutionary GPU called RacEr based on POSIT number system. Read more...

VividSparks products are designed to meet the constantly changing needs of the modern Data Center, providing up to 90X performance increase over CPUs for common workloads, including AI/ML, automotive computing, GPU acceleration and analytics.
With complex algorithms evolving faster than silicon design cycles, it’s impossible for fixed function GPU and CPU to keep pace. Our products provide reconfigurable acceleration that can adapt to continual algorithm optimizations, supporting any workload type while reducing overall cost of ownership. Read more...Neural Networks

The recent surge of interest in DNNs has led to increasingly complex networks that tax computational and memory resources. Many DNNs presently use16-bit or 32-bit floating point operations. Significant performance and power gains can be obtained when DNN accelerators supportlow-precision numerical formats. Despite considerable research, there is still a knowledge gap on how low-precision operations can be realized for both DNN training and inference. In thiswork, we propose a DNN architecture, Deep Positron, with posit numerical format operating successfully at ≤8 bits for inference. Read more...
Fixed point vs POSIT
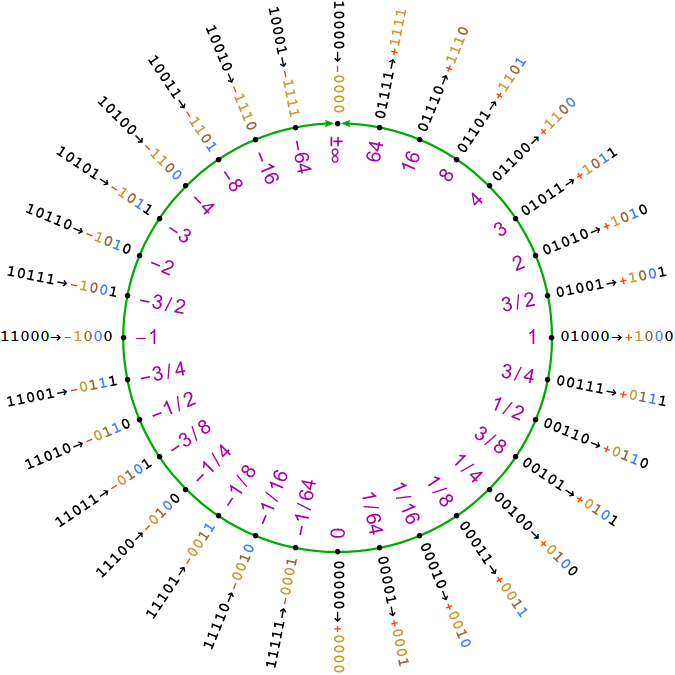
Performing the inference step of deep learning in resource constrained environments, such as embedded devices, is challenging. Success requires optimization at both software andhardware levels. Low precision arithmetic and specifically low precision fixed-point number systems have become the standard for performing deep learning inference. However, representingnon-uniform data and distributed parameters (e.g. weights) by using uniformly distributed fixed-point values is still a majordrawback when using this number system. Recently, the posit number system was proposed, which represents numbers in anon-uniform manner Read more...
POSIT on FPGAs

The failure of Dennard's scaling, the end of Moore's law and the recent developments regarding Deep Neural Networks (DNN) are leading computer scientists, practitioners and vendors to fundamentally revise computer architecture to look for potential performance improvements. One such candidate is to re-evaluate how floating point operations are performed, which have remained (nearly) unchanged for the past three decades. The POSIT numerical format was introduced in mid-2017 and is claimed to be more accurate, have a wider dynamical range and fewer unused states compared to the IEEE-754. Read more...
HPC

POSITs are a tapered precision real number system that provide efficient implementations of fused dot products, enabling tensor processing with fine-grain rounding error control to deliver error-free linear algebra. The fundamental constraint in delivering error-free computation is an explicit management of the accumulation of intermediate results in programmer visible quires. These quires are reasonable for posit arithmetic, but grow very large for floating-point arithmetic. This creates an insurmountable constraint for incorporating quires into a general-purpose CPU as the context switch state becomes too large to be practical. Read more...
Matrix Multiplication
Strassen’s recursive algorithm for matrix-matrix multiplication has seen slow adoption in practical applications despite being asymptotically faster than the traditionalalgorithm. A primary cause for this is the comparatively weaker numerical stability of its results. Techniques that aim to improve the errors of Strassen stand the risk of losingany potential performance gain. Moreover, current methods of evaluating such techniques for safety are overly pessimistic orerror prone and generally do not allow for quick and accurate comparisons. Read more...
Scientific Computing
Floating-point operations can significantly impact the accuracy and performance of scientific applications on large-scale parallel systems. Recently, an emerging floating-point format called Posit has attracted attention as an alternative to the standard IEEE floating-point formats because it could enable higher precision than IEEE formats using the same number of bits. In this work, we first explored the feasibility of Posit encoding in representative HPC applications by providing a 32-bit Posit NAS Parallel Benchmark (NPB) suite. Then, we evaluate the accuracy improvement in different HPC kernels compared to the IEEE 754 format. Read more...
Speech Recognition

Recurrent neural networks (RNNs) are now at the heart of many applications such as image captioning, speech recognition, languagetranslation and modeling. In order to achieve the best possible inference accuracy, these RNN models tend be quite large and many utilize 16 or 32-bit floating point format, which can enormouslystretch memory resources. Quantizing the model parameters in lower bit precision would be required in order to deploy these models to edge and mobile devices with limited memory storage.In this report, we study the impact of various bit precisions and formats on speech-to-text neural performance. A particular emphasisis given to the posit numerical format which can yield higher accuracy than floats for a specific range of numbers. For this purpose,we implemented a Python module which can convert float numbers into posits of various bit lengths. Our speech recognitioninference results show that the posit numerical format is by far the best solution for aggressive quantization at 8-bit. Read more...
Numerical Stability of POSITs
The Posit number format has been proposed by John Gustafson as an alternative to the IEEE 754 standard floatingpointformat. Posits offer a unique form of tapered precision whereas IEEE floating-point numbers provide the same relativeprecision across most of their representational range. Posits are argued to have a variety of advantages including better numericalstability and simpler exception handling. The objective of this paper is to evaluate the numerical stability of Posits for solving linear systems where we evaluateConjugate Gradient Method to demonstrate an iterative solver and Cholesky-Factorization to demonstrate a direct solver. Read more...
RacEr GP GPU

- May 2019, PR Department

- August 2019, PR Department

- September 2019, PR Department

- October 2019, PR Department
- March 2020, PR Department
- May 2021, PR Department
- June 2021, PR Department




POSIT number system is an alternative to Floating Point number system. POSIT number system provides large dynamic range, fewer exceptions and more accurate results compared to Floating Point number system. More information on POSIT numbers can be found at: https://en.wikipedia.org/wiki/Unum_(number_format)
VividarithmetiK Technology has arithmetic algorithms and circuits specifically tailored towards POSIT number system. It has the capability to compute two independent operations with only one instruction.
Yes, they are designed to be.
Yes, we have wrappers for different POSIT configurations which converts both ways.
Doing so not only reduces the hardware cost but also has the added advantage of improved performance. Adding one more processing element has the capability of executing 2 instructions in parallel but communication overhead and hardware cost increases along with performance degradation. Fusing 2 independent arithmetic operations together has very important applications in DSP, Graphics, AI, HPC and some automotive applications. Moreover, when you connect our cores in a Network on Chip topology, you can expect the throughput to be doubled.
No, our co-processors work as conventional FPUs but with POSIT number system along with super-fast arithmetic libraries.
Yes, we have our own POSIT C/C++ and Fortran compiler.
For product inquiries, sales, partnerships and more info.
Intel PAC cards are going to ship with VividSparks POSIT based accelerators.